Tagging Structures
— May 2012
A sketch of the cobbled-together tagging structure of my Pinboard bookmarks, elaborating on this conversation. It is shaped from the way I save and retrieve things for later use.
The primary goal is retrieval. There’s already four cues I can rely on when I’m trying to pull something I saved back out: the title, the URL, the highlights, and the timestamp. These are all highly specific, and if I have a clear memory of the thing, I’ll find it before I need to look at the tags.
So: the tags must work for when my recollection is hazy—I’m likely browsing, not searching. I’ll look at a tag collection, and then narrow down the results with more precise tags until I find it. Tags have cascading levels of specificity: publishing > journalism > reading > narrative, for example, letting me jump in at whatever scale that I can remember. A useful rule-of-thumb is to name these tags what I’m likely to search for later, which sometimes feels like future sight.
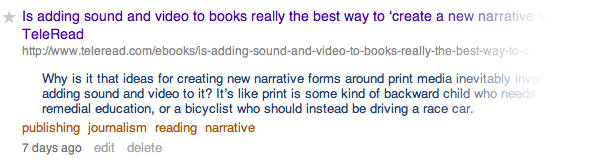
As fallback, I have 10 tags at the top level: technology, education, life, publishing, political, society, design, history, art, and food. Some of these things overlap, and that’s ok: they reflect the way I mentally sort what I find and read. Everything should be tagged at least one of these lead tags, and they are the starting points when I remember almost nothing about what I’m looking for.

This gives me a naming framework at the moment of tagging, too: I start with the lead tag and then describe the bookmark with broad categories, gradually getting more specific (the same way one would carve at sculpture), and then I skim through the article and my highlights again to add any individual triggers: names and highly specific concepts tend to be dropped in here. Specific uses (say, shopping) or projects also come at the end.
The triggers at the end of each tag chain aren’t useful as filters for browsing, but they serve other functions: if I go to the page of items tagged technology (which is pretty vague), the hyper-specific tags give me a good idea of what’s in it. So they’re useful as an overview tool, when I want to know what’s in a broad category without reading through all my highlights.
How granular a particular tag actually is can change as time passes. If I’m interested in the subject and do deeper research, what was once a pretty specific tag (say, London) becomes a broad roof that houses many more discrete ideas.
This allows for frequent and quick reflection: after a few hours of digging into things about London, I can go to the London tag page and get a sweeping overview of what I found, with the broader ideas emerging pretty clearly from the number of items with the same tag. This is also a good time to combine similarly worded tags: such as ships with boats if it looks like I was just using the two terms interchangeably.
The cascade structure lets me roughly see what level of granularity I’m at, just by glancing at the order of the tags in an individual bookmark. I find this fuzzy but clear enough to not need hierarchical tagging in Pinboard.
This is a continuously evolving system: my bookmarks from even half a year ago looks different from my bookmarks now. This sometimes gives me trouble when I get confused by things tagged out of order, or by outdated naming conventions (I try to tag all people names as firstname-lastname now). So, careful and diligent pruning is necessary to keep this system coherent.